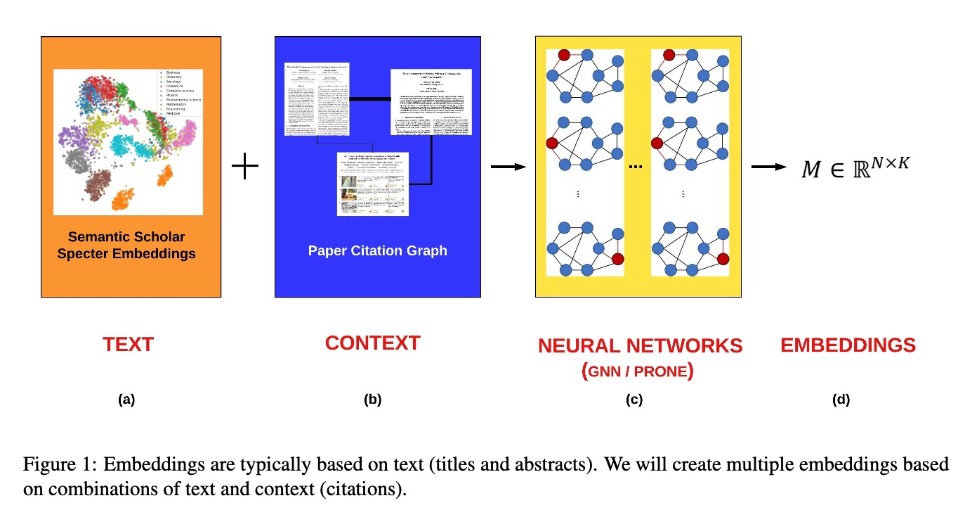
As seen in Figure 1, it is standard practice to represent documents, (a), as embeddings, (d). We will do this in multiple ways. Embeddings based on deep nets (BERT) capture text and other embeddings based on node2vec and GNNs (graph neural nets), (c), capture citation graphs, (b). Embeddings encode each of N ≈ 200M documents as a vector of K ≈ 768 hidden dimensions. Cosines of two vectors denote similarity of two documents. We will evaluate these embeddings and show that combinations of text and citations are better than either by itself on standard benchmarks of downstream tasks.
As deliverables, we will make embeddings available to the community so they can use them in a range of applications: ranked retrieval, recommender systems and routing papers to reviewers. Our interdisciplinary team will have expertise in machine learning, artificial intelligence, information retrieval, bibliometrics, NLP and systems. Standard embeddings are time invariant. The representation of a document does not change after it is published. But citation graphs evolve over time. The representation of a document should combine time invariant contributions from the authors with constantly evolving responses from the audience, like social media.
We will build several different embeddings of documents from Semantic Scholar,1 a collection of N ≈ 200 million documents from seven sources: (1) Microsoft Academic Graph (MAG),2 (2) DOI,3 (3) PubMed,4 (4) PubMedCentral,5 (5) DBLP,6 (6) ArXiv7 and (7) the ACL Anthology.8 Since Semantic Scholar plays such a central role in this project, we are fortunate to have Maria Antoniak and Sergey Feldman on our team. They are members of the Semantic Scholar group at the Allen Institute for Artificial Intelligence. Semantic Scholar is a signif- icant effort involving more than 50 people working over 7 years. Semantic Scholar has more than 8M monthly active users. Another team member, Hui Guan, provides expertise in Systems, which will be useful since scale is a challenge for many of the methods discussed below.
An embedding is a dense matrix, M ∈ ℜ N x K, where K is the number of hidden dimensions. The rows in M represent documents. Cosines of two rows estimate the similarity of two documents. Some embeddings, Mt, are text-based, and other embeddings, Mc, are context-based:
We can construct examples of Mt and Mc from resources from Semantic Scholar:
We will start with Specter Embeddings as an example of Mt and a node2vec (Grover and Leskovec, 2016) encodings of the citation graph as an example of Mc. Node2vec maps a graph (sparse N × N Boolean matrix) toadensematrixin RN×K Our first example of Mc will use node2vec to construct an embedding from the citation graph. Specter embeddings and citation graphs will be downloaded from Semantic Scholar. A number of node2vec methods are supported under nodevectors.9 ProNE (Zhang et al., 2019) is particularly promising. Many node2vec methods are based on deep nets, but ProNE is based on SVD. We will also experiment with GNNs10 for combining text embeddings with citation graphs.
Much of the recent excitement over embeddings started with (Devlin et al., 2018), though embeddings have been important in Information Retrieval for at least thirty years (Deerwester et al., 1990). The older bag-of-word methods have some advantages over more recent methods that are limited to the first 512 subword units. Node2vec can be viewed in terms of spectral clustering; cosines of node2vec embeddings are related to random walks on graphs.
More sophisticated versions of Mc will take advantage of citing sentences. We believe that citing sentences will help with terms such as “Turing Machine.” That term is common in sentences that cite Turing et al. (1936), even though the term does not appear in Turing’s paper, since he did not name anything after himself.
Some embeddings evolve over time, and some do not. Since the text does not change after a paper is published, Mt also does not change after publication. However, Mc evolves as more and more papers are published over time. We like to think of the literature as a conversation like social media. The value of a paper combines (time invariant) contributions from authors with (monotonically increasing) contributions from the audience.
This project will distribute resources (embeddings) and tools (programs and/or APIs) for ranked re- trieval, routing and recommending papers to read and/or cite. In addition, we will enhance our theo- retical understanding of deep nets by making con- nections with SVD. The routing application is of particular interest since many conferences assign papers to reviewers with software that may not work well, and may benefit from additional testing.
Evaluations will show that some embeddings are better for capturing text (Figure 1a) and other embeddings are better for capturing context (Figure 1b). Combinations of these embeddings (Figure 1d) are better than either by itself.
Evaluations will be based on a number of benchmarks including MAG240M11 and SciRepEval.12 Evaluation of routing systems will use materials from (Mimno and McCallum, 2007).
1 https://www.semanticscholar.org/product/api
2 https://www.microsoft.com/en-us/research/project/microsoft-academic-graph/
4 https://pubmed.ncbi.nlm.nih.gov/
5 https://www.ncbi.nlm.nih.gov/pmc/
9 https://github.com/VHRanger/nodevectors
10 https://snap-stanford.github.io/cs224w-notes/machine-learning-with-networks/graph-neural-networks/
Full-time members
Senior reserchers
Junior researchers
Undergrade students
Part-time members
Martin Dočekal (Brno University of Technology)
Jiameng Sun (Northeastern University)