Abstract
Speaker diarization aims at answering the question of “who speaks when” in a recording. It is a key task for many speech technologies such as automatic speech recognition (ASR), speaker identification and dialog monitoring in different multi-speaker scenarios, including TV/radio, meet- ings, and medical conversations. In many domains, such as health or human-machine interactions, the prediction of speaker segments is not enough and it is necessary to include additional para- linguistic information (age, gender, emotional state, speech pathology, etc.). However, most existing real-world applications are based on mono-modal modules trained separately, thus resulting in sub-optimal solutions. In addition, the current trend for explainable AI is a vital process for transparency of decision-making with machine learning: the user (a doctor, a judge, or a human scientist) has to justify the choice made on the basis of the system output.
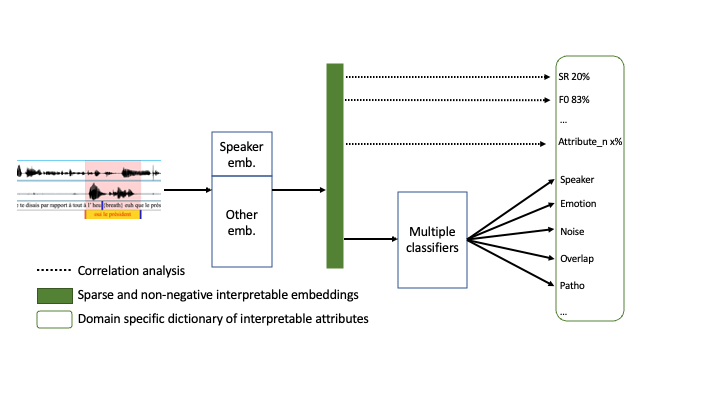
This project aims at converting these outputs into interpretable clues (mispronounced phonemes, low speech rate, etc.) which explains the automatic diarization. While the question of simultaneously performed speech recognition and speaker diarization has been addressed under JSALT 2020, this proposal intends to develop a multi-task diarization system based on a joint latent representation of speaker and para-linguistic information. The latent representation embeds multiple modalities such as acoustic and linguistic or vision. This joint embedding space will be projected into a sparse and non-negative space in which all dimensions are interpretable by design. In the end, the diarization output will be a rich segmentation where speech segments are characterized with multiple labels, and interpretable attributes derived from the latent space as depicted in Figure 1.
1. Develop a multi-task speech segmentation system which returns multiple labels on the basis of a joint multi-modal latent representation of speaker and para-linguistic characteristics.
2. Learn a sparse and non-negative latent space where each dimension is an interpretable by-design clue and evaluate objectively and subjectively how interpretable it is.
• Develop a multi-task diarization system based on a joint multi-modal latent representation of speaker and para-linguistic information [feb-june 2023]
Currently, SSL representations already exists for speaker (x-vectors) and speech processing (WavLM [Chen et al., 2022]). On the one hand, EEND [Horiguchi et al., 2020] can predict multiple speakers at a time, thus partially solving speech overlap. On the other hand, recent segmentation by classification task-dependent systems, allow to precisely segment the audio content with multiple sound events such as music, speech, noise or overlap. The first task of this project will be to merge and expand the specific representation spaces and SSL embeddings in a multi-modal common space by the exploration of recent adaptation techniques such as adapters and transfer learning. The use of this common space should not degrade independent sub-tasks performances.
• Define domain-specific dictionary for interpretable attributes [feb-june 2023]
Most of the existing approaches for neural networks explainability have been experimented in images or textual data for which objects and words usually define the dictionary of interpretable attributes. The first stage towards interpretability addressed by this project is the definition of a suitable domain-specific ontology for speech in the continuous temporal space. As a starting point, possible attributes can be phonetic traits [Abderrazek et al., 2022] or speech attributes derived from the source-filter model.
• Project latent embeddings into an interpretable space [june-july 2023]
The second stage consists in learning an embedding space where dimensions are interpretable by design. The project will explore different techniques among a) SPINE [Subramanian et al., 2018], which consists in learning sparse and non-negative embeddings, b) important local features with Shapley values [Lundberg and Lee, 2017], c) identity initialization for layer-wise interpretation [Kubota et al., 2021] or d) binary attributes for the quantification of the contribution of each dimension to the global score [Amor and Bonastre, 2022].
• Design the first human evaluation protocol for interpretability in speech [june-dec 2023]
Very few studies have tackled the question of how to measure interpretability with objective and subjective metrics, particularly for speech. By gathering internationally recognized speech researchers, JSALT is a unique opportunity to overcome this challenge. Before and during the Workshop, correlations (CCA, LMM) between speech/speaker characteristics and interpretable attributes will be analyzed with respect to domain robustness. Human correction of predicted labels will be used as a proxy to investigate how interpertable are the attributes. The final evaluation plan involving human annotators will quantify interpretability by the use of common sense in intrusion tests [Subramanian et al., 2018]. The human evaluation itself will take place after the workshop.
All systems will be evaluated with standard segmentation (DER, SER, purity and coverage) and classification metrics (f1-score, recall, SNR). The final goal of our team is to propose an interpretable embedding space which do not degrade the performances on all sub-tasks with mainstream databases (DiHard, Albyzin, Allies, etc.). By the end of the Workshop, we will release open-source baseline systems, evaluation, metrics and data for their evaluation. The team, leaded by Marie Tahon (LIUM), gathers speaker diarization, segmentation, emotion recognition and pathological voices experts, with a high diversity of origin (US, Argentina, Europe) and gender. Most of the members are funded by the European project Esperanto.
[Abderrazek et al., 2022] Abderrazek, S., Fredouille, C., Ghio, A., Lalain, M., Meunier, C., and Woisard, V. (2022). Towards Interpreting Deep Learning Models to Understand Loss of Speech Intelligibility in Speech Disorders Step 2. In ICASSP, pages 7387–7391.
[Amor and Bonastre, 2022] Amor, I. B. and Bonastre, J.-F. (2022). BA-LR: Binary-Attribute-based Likelihood Ratio estimation for forensic voice comparison. In International Workshop on Biometrics and Forensics (IWBF), pages 1–6.
[Chen et al., 2022] Chen, S., Wang, C., Chen, Z., Wu, Y., Liu, S., and et al., Z. C. (2022). WavLM: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518.
[Horiguchi et al., 2020] Horiguchi, S., Fujita, Y., Watanabe, S., Xue, Y., and Nagamatsu, K. (2020). End-to-End Speaker Diarization for an Unknown Number of Speakers with Encoder-Decoder Based Attractors. arXiv:2005.09921 [cs, eess].
[Kubota et al., 2021] Kubota, S., Hayashi, H., Hayase, T., and Uchida, S. (2021). Layer-wise interpretation of deep neural networks using identity initialization. In ICASSP, pages 3945–3949.
[Lundberg and Lee, 2017] Lundberg, S. M. and Lee, S.-I. (2017). A Unified Approach to Interpreting Model Predictions. NIPS, pages 4768–4777.
[Subramanian et al., 2018] Subramanian, A., Pruthi, D., Jhamtani, H., Berg-Kirkpatrick, T., and Hovy, E. (2018). SPINE: sparse interpretable neural embeddings. In AAAI Conference on Artificial Intelligence, pages 4921–4928.
Full-time members
Senior Researchers
Junior Researchers
Undergrade students
Part-time / Other potential members