Many advanced technologies such as Voice Search, Assistant Devices (e.g. Alexa, Cortana, Google Home, ...) or Spoken Machine Translation systems are using speech signals as input. These systems are built in two ways:
In this project we are seeking for a speech representation interface which has the advantages of both the End-to-End and cascade systems while it does not suffer from the drawbacks of these methods.
[R1] has proposed a finite state lattice based interpretation of all the common training criteria in speech recognition. The weights of this lattice are computed by a neural network directly built on the top of the speech signal. An example of such lattice is shown in Fig1 (copied from Figure 1 of [R1]). We will use this lattice as a dense representation of the speech signal. Such a lattice already possesses most of the properties listed for a speech representation. In this workshop, we would like to extend this representation with the focus on the following problems:
Furthermore, we would like to collaborate with other sub-teams in the following problems:
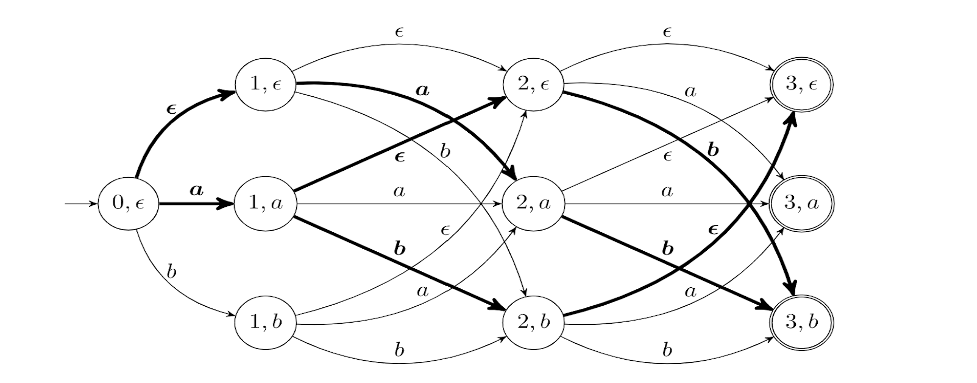
Figure 1: Dense trellis representing the Q x T output of an ASR-based neural network. Q is the neural network output dimension and T is the input sequence length.
The lattice-based speech representation can be further modified, enriched or compressed through classical Finite State Transducer (FST) operations such as composition, intersection, pruning, ... and finally passed to downstream systems. To guarantee differentiability and hardware portability (GPU / CPU) – essential requirements for any machine learning pipeline - we propose to revisit the FST framework through the lens of sparse linear algebra. Indeed, expressing FST operations in terms of matrix-vector multiplications (or similar linear operator) greatly facilitates the computation of gradients for a broad range of semiring and makes GPU-based implementation trivial.
Most ASR research rely on the simplifying assumption that speech is pre-segmented in short duration utterances usually lasting a few seconds. This assumption is however rarely met in practice. Moreover, the task of segmenting long audio recordings is costly and challenging and remains an open issue. We propose to use our FST-based speech representations to efficiently tackle this problem. The idea is to rely on a sparse linear algebra interpretation of the FST framework to implement a fast, memory efficient and streaming version of the forward-backward and Viterbi algorithm for aligning and segmenting long recordings. The crux of the method is to :
We plan to evaluate this work by measuring the WER of downstream ASR systems trained on the provided segments.
Speech-based technologies find applications in a wide variety of environments : computing cluster, personal computer, smartphone, embedded devices, ... However, the ASR pipeline is hard to adapt to all these targets especially the ones with memory and computing limited resources. More precisely, the inference part of the ASR pipeline is often the bottleneck : in many situations it can take up to 75% of the processing time. We want to demonstrate that our FST-based representations - since they are based on sparse-matrices – are highly efficient and can adapt well in a wide range of computing environments. We propose to benchmark inference with our FST-based representation against other competitive baselines such as Kalid or k2 on different devices : raspberry pi (i.e. the edge), personal computer and GPU-based environment (i.e. the cloud). To provide a fine-grain analysis we propose to measure the processing time and the memory bandwidth and the efficiency (in FLOPS) of different implementations / representations.
Finally, we propose to go one step further and show how our FST-based speech representations can help in a distributed inference environment. Indeed, one can guess the amount of work needed for inference based on different characteristics of the FSTs (effective beam size, sparsity level, ...) allowing therefore to decide on a per-case basis how and on which node of the distributed system to run the inference. For this project we propose to demonstrate this ability by making a small scale prototype of an edge-cloud distributed system with 2 agents (1 small, 1 big) that chooses the inference target based on the nature of the FST-based neural network output.
[R1] E. Variani, K. Wu, M. Riley, D. Rybach, M. Shannon, C. Allauzen, “Global normalization for streaming speech recognition in a modular framework”, Neurips 2022
[R2] K. Wu, E. Variani, T. Bagby, M. Riley, “LAST: Scalable lattice-based speech modeling in jax”, Submitted to ICASSP 2023
Full time members
Senior Researchers
Junior Researchers
Undergrade students
Part-time / Other potential members